
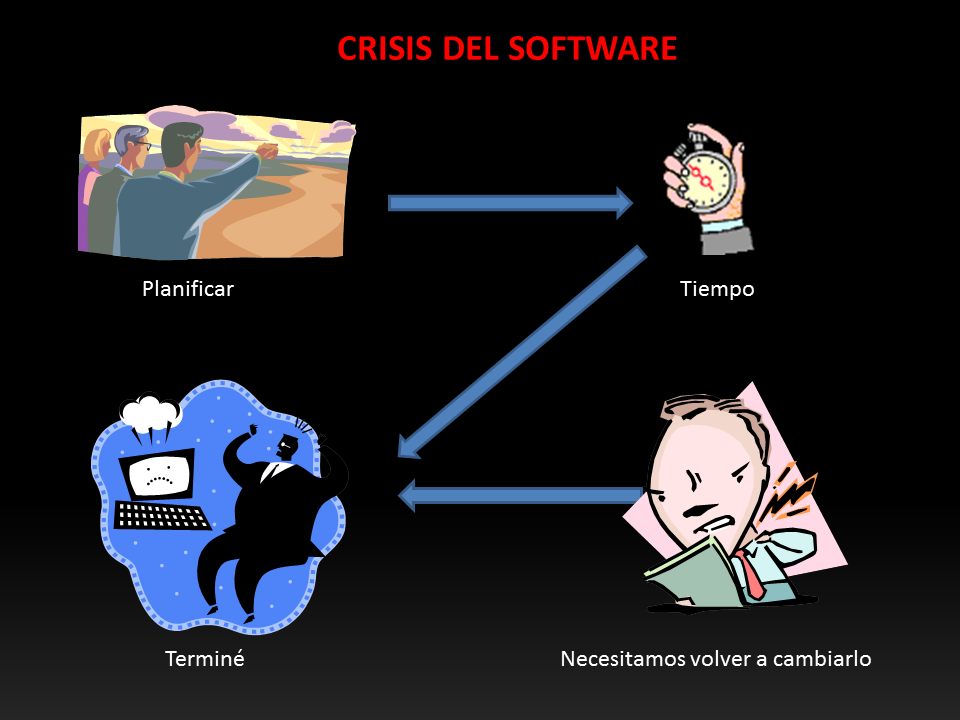
La crisis del software se fundamentó en el tiempo de creación de software, ya que en la creación del mismo no se obtenían los resultados deseados, además de un gran costo y poca flexibilidad.
Básicamente, la crisis del software se refiere a la dificultad en escribir programas libres, la complejidad que supone la tarea de programar, y los cambios a los que se tiene que ver sometido un programa para ser continuamente adaptado a las necesidades de los usuarios.
Además, no existen todavía herramientas que permitan estimar de una manera exacta, antes de comenzar el proyecto, cuál es el esfuerzo que se necesitará para desarrollar un programa. Este hecho provoca que la mayoría de las veces no sea posible estimar cuánto tiempo llevará un proyecto, ni cuánto personal será necesario. Cuando se fijan plazos normalmente no se cumplen por este hecho. Del mismo modo, en muchas ocasiones el personal asignado a un proyecto se incrementa con la esperanza de disminuir el plazo de ejecución.
Por último, las aplicaciones de hoy en día son programas muy complejos, inabordables por una sola persona. En sus comienzos se valoró como causa también la inmadurez de la ingeniería de software, aunque todavía hoy en día no es posible realizar estimaciones precisas del coste y tiempo que necesitará un proyecto de software.
Englobó a una serie de sucesos que se venían observando en los proyectos de desarrollo de software:
- Los proyectos no terminaban en plazo.
-Los proyectos no se ajustaban al presupuesto inicial.
- Baja calidad del software generado.
- Software que no cumplía las especificaciones.
- Código inmantenible que dificultaba la gestión y evolución del proyecto.
Aunque se han propuesto diversas metodologías para intentar subsanar los problemas mencionados, lo cierto es que todavía hoy no existe ningún método que haya permitido estimar de manera fiable el coste y duración de un proyecto antes de sus comienzos.






{kind=link}